Jaxoplanet core from scratch#
Inspired by the autodidax tutorial from the JAX documentation, in this tutorial we work through implementing some of the core jaxoplanet functionality from scratch, to demonstrate and discuss the choices made within the depths of the codebase.
For now, we only cover the included solver for Kepler’s equation, but we hope to include some discussion of the light curve models in a later edition because those include some interesting tradeoffs and other details.
Solving Kepler’s equation#
One core piece of infrastructure provided by jaxoplanet is a function to solve Kepler’s equation
for the eccentric anomaly \(E\) as a function of the eccentricity \(e\) and mean anomaly \(M\). This an important operation for many exoplanet models since the eccentric anomaly describes the motion of a bound two body gravitational system.
There is a lot of literature dedicated to solving this equation efficiently and robustly, and we won’t get into all the details here, but there are a few points we should highlight:
The methods that are most commonly used in astrophysics to solve this equation are all iterative, using some sort of root finding scheme. While these methods can work well, they tend to be less computationally efficient than non-iterative approaches. Even more importantly for our purposes, non-iterative methods are better suited to massively parallel compute architectures like GPUs. These non-iterative methods typically have a two step form: (i) make a good initial guess (“starter”) for \(E\), then (ii) use a high order root finding update to refine this estimate.
In most Python codes, the Kepler solver is offloaded to a compiled library, but we will find that we can get comparable performance just using JAX, and relying on its JIT compilation to accelerate the computation.
With these points in mind, we can implement the solver that is included with jaxoplanet.
Pure-Python (+JAX) solver#
The solver that we use in jaxoplanet is based on the method from Markley (1995).
It is possible to get better CPU performance using more sophisticated methods (see, for example, Raposo-Pulido & Peláez 2017, and the follow up Brandt et al. 2021), but these methods are somewhat harder to implement efficiently using JAX’s programming model, and we expect that they would not be so easily extensible to GPU or TPU acceleration.
Regardless, we find that JAX’s JIT compilation allows us to achieve nearly state-of-the-art runtime performance, even with this simple method.
First we implement a “starter” function which uses Markley’s approximation to estimate \(E\) as a function of \(M\) and \(e\):
import jax
import jax.numpy as jnp
# Enabling double precision for comparison with standard methods from
# the literature, but everything here also works at lower precision
jax.config.update("jax_enable_x64", True)
def kepler_starter(mean_anom, ecc):
ome = 1 - ecc
M2 = jnp.square(mean_anom)
alpha = 3 * jnp.pi / (jnp.pi - 6 / jnp.pi)
alpha += 1.6 / (jnp.pi - 6 / jnp.pi) * (jnp.pi - mean_anom) / (1 + ecc)
d = 3 * ome + alpha * ecc
alphad = alpha * d
r = (3 * alphad * (d - ome) + M2) * mean_anom
q = 2 * alphad * ome - M2
q2 = jnp.square(q)
w = jnp.square(jnp.cbrt(jnp.abs(r) + jnp.sqrt(q2 * q + r * r)))
return (2 * r * w / (jnp.square(w) + w * q + q2) + mean_anom) / d
Then we implement a third order Householder update to refine this estimate:
def kepler_refiner(mean_anom, ecc, ecc_anom):
ome = 1 - ecc
sE = ecc_anom - jnp.sin(ecc_anom)
cE = 1 - jnp.cos(ecc_anom)
f_0 = ecc * sE + ecc_anom * ome - mean_anom
f_1 = ecc * cE + ome
f_2 = ecc * (ecc_anom - sE)
f_3 = 1 - f_1
d_3 = -f_0 / (f_1 - 0.5 * f_0 * f_2 / f_1)
d_4 = -f_0 / (f_1 + 0.5 * d_3 * f_2 + (d_3 * d_3) * f_3 / 6)
d_42 = d_4 * d_4
dE = -f_0 / (f_1 + 0.5 * d_4 * f_2 + d_4 * d_4 * f_3 / 6 - d_42 * d_4 * f_2 / 24)
return ecc_anom + dE
Putting these together, we can construct a solver function which includes some extra bookkeeping to handle the range reduction of the inputs:
@jax.jit
@jnp.vectorize
def kepler_solver_impl(mean_anom, ecc):
mean_anom = mean_anom % (2 * jnp.pi)
# We restrict to the range [0, pi)
high = mean_anom > jnp.pi
mean_anom = jnp.where(high, 2 * jnp.pi - mean_anom, mean_anom)
# Solve
ecc_anom = kepler_starter(mean_anom, ecc)
ecc_anom = kepler_refiner(mean_anom, ecc, ecc_anom)
# Re-wrap back into the full range
ecc_anom = jnp.where(high, 2 * jnp.pi - ecc_anom, ecc_anom)
return ecc_anom
And that’s it! Now we have a solver for Kepler’s equation that we can use from JAX.
Some notes:
We’ve called this function
kepler_solver_implrather thankepler_solver, for reasons that we will get into shortly.This function was decorated with the
jax.numpy.vectorizefunction which, while not strictly necessary in this case, is useful because it signals that we have implemented our solver for scalar inputs and we let JAX handle the vectorization to arrays of different shapes. Unlikenumpy.vectorize, the JAX version incurs no runtime overhead when vectorizing.
To check to make sure that our implementation works, let’s make sure that that our method actually solves the equation of interest. We start by generating a grid of known eccentric anomalies and computing the corresponding array of mean anomalies using Kepler’s equation. Then we make sure that our solver returns the correct values.
import matplotlib.pyplot as plt
ecc = 0.5
true_ecc_anom = jnp.linspace(0, 2 * jnp.pi, 50_000)[:-1]
mean_anom = true_ecc_anom - ecc * jnp.sin(true_ecc_anom)
calc_ecc_anom = kepler_solver_impl(mean_anom, ecc)
plt.plot(true_ecc_anom, jnp.abs(calc_ecc_anom - true_ecc_anom), "k")
plt.axhline(0, color="k")
plt.xlabel("eccentric anomaly")
plt.ylabel(r"error from Kepler solver");
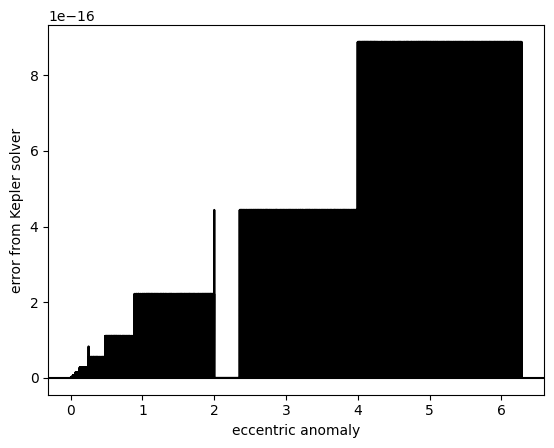
We enabled double precision above (although that is by no means a requirement for this code), and we can see here that the results are correct to within \(<10^{-15}\) of absolute error, which should do just fine for any practical applications. This error does increase for large eccentricities, but even then it should always perform better than \(\sim 10^{-12}\), and a full analysis is beyond the scope of this tutorial.
It’s also worth testing the performance of this implementation. Since we execute these tutorials on Read the Docs, the specific results here will depend on the actual allocated hardware, but here’s how you would benchmark this operation on your system:
# Using a large number of test values to minimize effects of Python overhead
mean_anom_bench = jax.device_put(
jnp.linspace(0, 2 * jnp.pi, 500_000)[:-1]
).block_until_ready()
kepler_solver_impl(mean_anom_bench, ecc).block_until_ready()
%timeit kepler_solver_impl(mean_anom_bench, ecc).block_until_ready()
33.7 ms ± 148 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
On my 2020 M1 MacBook Pro, I get a runtime of 7 ms per loop, and in each loop we’re solving Kepler’s equation 500,000 times, so that means that each solve costs about 14 ns.
For comparison, on the same system, the Kepler solver from RadVel which is implemented in C/Cython takes 35 ms per loop.
We should note that the point here is not to pick on RedVel, and let’s be clear that this is by no means a complete comparison! Instead, we want to highlight that in some cases JIT-compiled JAX code can get similar performance to that provided by optimized low level code with Python bindings.
Another benefit of this pure-JAX implementation is that it can be natively executed on hardware accelerators like a GPU or TPU.
For comparison, on an Nvidia V100 GPU, the above benchmark takes about 0.1 ms (nearly 2 orders of magnitude faster than my CPU).
Supporting differentiation#
Another key feature of JAX (besides the fact that its JIT compiler produces very fast code) is that it supports automatic differentiation.
While it is already possible to differentiate the above code, that wouldn’t produce the most efficient method, since tracing through the kepler_solver_impl to obtain the derivative is suboptimal when we can explicitly write the derivative given below.
Instead, we can use the implicit function theorem to derive the “Jacobian-vector product” required by JAX’s machinery.
To do that, we differentiate Kepler’s equation from above and rearrange:
The key point here is that we can easily evaluate the “coefficients” in the above expression at a given value of \(E\).
Using this expression, here’s how we can implement our jax.custom_jvp rule (see the JAX docs for more info):
from jax.interpreters import ad
@jax.custom_jvp
def kepler_solver(mean_anom, ecc):
return kepler_solver_impl(mean_anom, ecc)
@kepler_solver.defjvp
def kepler_solver_jvp(primals, tangents):
mean_anom, ecc = primals
d_mean_anom, d_ecc = tangents
# Run the solver from above to compute `ecc_anom`
ecc_anom = kepler_solver(mean_anom, ecc)
# Propagate the derivatives using the implicit function theorem
dEdM = 1 / (1 - ecc * jnp.cos(ecc_anom))
dEde = jnp.sin(ecc_anom) * dEdM
d_ecc_anom = dEdM * make_zero(d_mean_anom) + dEde * make_zero(d_ecc)
return ecc_anom, d_ecc_anom
def make_zero(tan):
# This is a helper function to handle symbolic zeros (i.e. parameters
# that are not being differentiated)
if type(tan) is ad.Zero:
return ad.zeros_like_aval(tan.aval)
else:
return tan
Given this final kepler_solver function, we can take a look at the derivatives of the eccentric anomaly as a function of mean anomaly and eccentricity.
By default JAX only supports differentiation of scalar functions, but combining jax.grad with jax.vmap we can get efficient computation of the elementwise derivatives of this function.
def elementwise_grad(argnums):
return jax.vmap(jax.grad(kepler_solver, argnums=argnums), in_axes=(0, None))
fig, axes = plt.subplots(3, 1, sharex=True)
ax = axes[0]
ax.plot(mean_anom, kepler_solver(mean_anom, ecc), "k")
ax.set_ylabel("E")
ax = axes[1]
ax.plot(mean_anom, elementwise_grad(0)(mean_anom, ecc), "k")
ax.set_ylabel("dE / dM")
ax = axes[2]
ax.plot(mean_anom, elementwise_grad(1)(mean_anom, ecc), "k")
ax.set_xlabel("mean anomaly; M")
ax.set_ylabel("dE / de")
ax.set_xlim(0, 2 * jnp.pi);
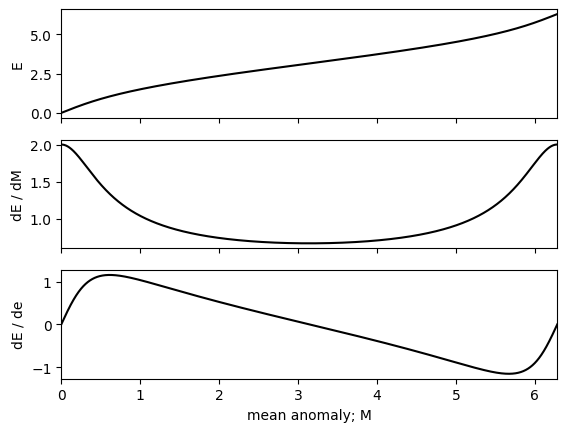
Finally, we can test the performance of this operation to see that the computational cost is still dominated by the solve. In other words, the total cost of the of computing these derivatives is only fractionally (about 1% on my laptop) higher than just solving the equation itself.
grad_func = jax.jit(elementwise_grad((0, 1)))
grad_func(mean_anom_bench, ecc)[1].block_until_ready()
%timeit grad_func(mean_anom_bench, ecc)[1].block_until_ready()
42.3 ms ± 173 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Above we simply asserted that running autodiff directly on the original kepler_solver_impl function, instead of the version with closed form derivatives, wouldn’t produce the most efficient computation.
Here we can test that by measuring the runtime of computing these gradients using autodiff directly on the solver code:
grad_func = jax.vmap(jax.grad(kepler_solver_impl, argnums=(0, 1)), in_axes=(0, None))
grad_func(mean_anom_bench, ecc)[1].block_until_ready()
%timeit grad_func(mean_anom_bench, ecc)[1].block_until_ready()
136 ms ± 4.15 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
On my laptop, this is about a factor of 6 slower than our closed form version above.